Sharded Matrices and How to Multiply Them
Part 3 of How To Scale Your Model (Part 2: TPUs | Part 4: Transformer Math)
When we train large ML models, we have to split (or "shard") their parameters or inputs across many accelerators. Since LLMs are mostly made up of matrix multiplications, understanding this boils down to understanding how to multiply matrices when they're split across devices. We develop a simple theory of sharded matrix multiplication based on the cost of TPU communication primitives.
Partitioning Notation and Collective Operations
When we train an LLM on ten thousand TPUs or GPUs, we’re still doing abstractly the same computation as when we’re training on one. The difference is that our arrays don’t fit in the HBM of a single TPU/GPU, so we have to split them.
Here’s an example 2D array A sharded across 4 TPUs:

Note how the sharded array still has the same global or logical shape as the unsharded array, say (4, 128), but it also has a device local shape, like (2, 64), which gives us the actual size in bytes that each TPU is holding (in the figure above, each TPU holds ¼ of the total array). Now we’ll generalize this to arbitrary arrays.
A unified notation for sharding
We use a variant of named-axis notation to describe how the tensor is sharded in blocks across the devices: we assume the existence of a 2D or 3D grid of devices called the device mesh where each axis has been given mesh axis names e.g. X, Y, and Z. We can then specify how the matrix data is laid out across the device mesh by describing how each named dimension of the array is partitioned across the physical mesh axes. We call this assignment a sharding.
Example (the diagram above): For the above diagram, we have:
- Mesh: the device mesh above
Mesh(devices=((0, 1), (2, 3)), axis_names=('X', 'Y')), which tells us we have 4 TPUs in a 2x2 grid, with axis names $X$ and $Y$. - Sharding: $A[I_X, J_Y]$, which tells us to shard the first axis, $I$, along the mesh axis $X$, and the second axis, $J$, along the mesh axis $Y$. This sharding tells us that each shard holds $1 / (\lvert X\rvert \cdot \lvert Y\rvert)$ of the array.
Taken together, we know that the local shape of the array (the size of the shard that an individual device holds) is $(\lvert I\rvert / 2, \lvert J\rvert / 2)$, where \(\lvert I\rvert\) is the size of A’s first dimension and \(\lvert J\rvert\) is the size of A’s second dimension.
Pop Quiz [2D sharding across 1 axis]: Consider an array fp32[1024, 4096] with sharding $A[I_{XY}, J]$ and mesh {'X': 8, 'Y': 2}. How much data is held by each device? How much time would it take to load this array from HBM on H100s (assuming 3.4e12 memory bandwidth per chip)?
Click here for the answer.
$A[I_{XY}, J]$ shards the first dimension (I) along both the X and Y hardware axes. In this example, the local shape is $(\lvert I\rvert /(\lvert X\rvert \cdot \lvert Y\rvert), \lvert J\rvert)$. For the given example, the global shape is fp32[1024, 4096], so the local shape is fp32[64, 4096].
Since each GPU has 4 * 64 * 4096 = 1MiB bytes, this would take about 1e6 / 3.4e12 = 294ns, although likely significantly more due to various overheads since this is so small.
Visualizing these shardings: Let’s try to visualize these shardings by looking at a 2D array of data split over 4 devices:

We write the fully-replicated form of the matrix simply as $A[I, J]$ with no sharding assignment. This means that each device contains a full copy of the entire matrix.

We can indicate that one of these dimensions has been partitioned across a mesh axis with a subscript mesh axis. For instance $A[I_X, J]$ would mean that the I logical axis has been partitioned across the X mesh dimension, but that the J dimension is not partitioned, and the blocks remain partially-replicated across the Y mesh axis.

$A[I_X, J_Y]$ means that the I logical axis has been partitioned across the X mesh axis, and that the J dimension has been partitioned across the Y mesh axis.

We illustrate the other possibilities in the figure below:
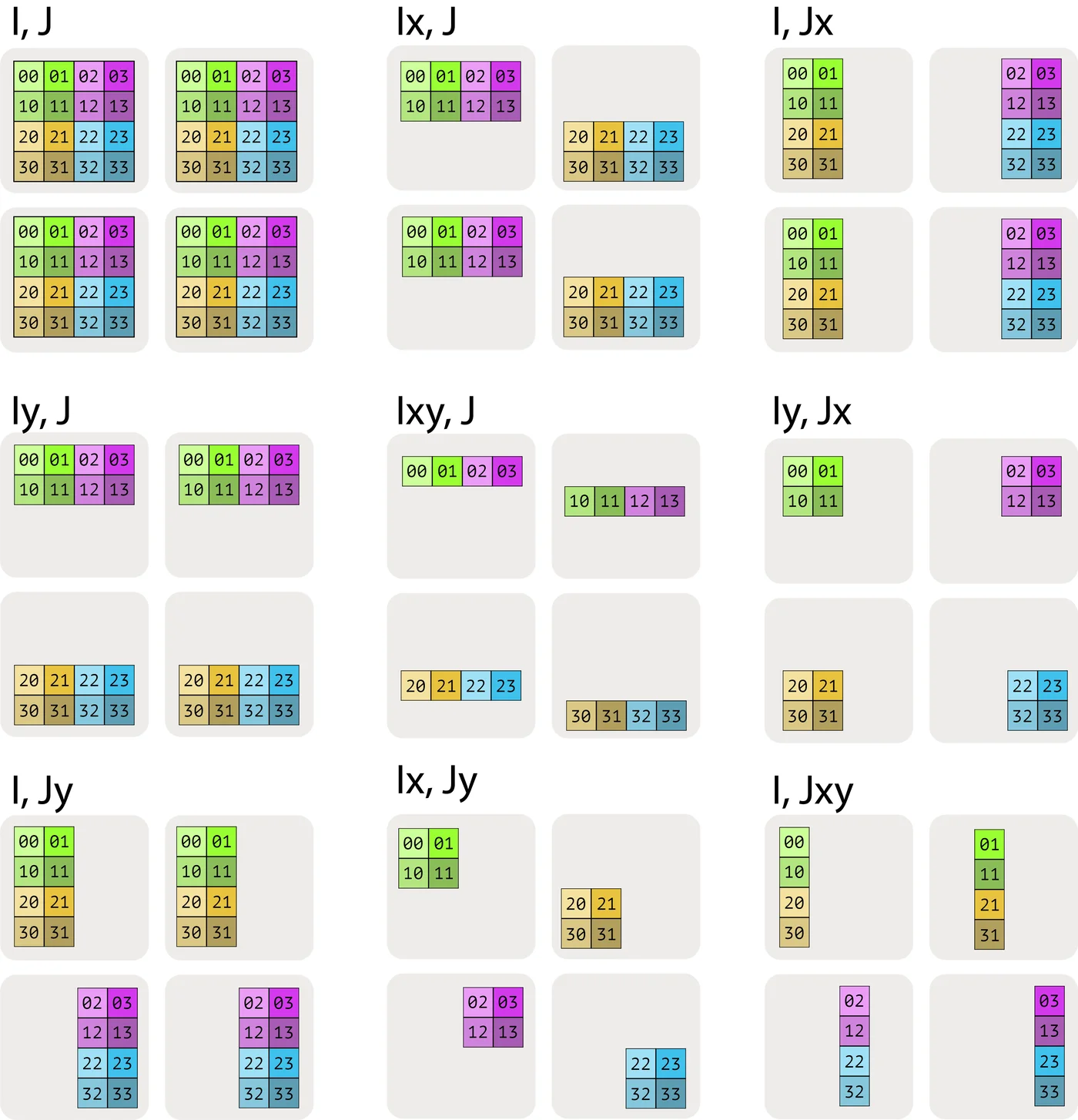
Here $A[I_{XY}, J]$ means that we treat the X and Y mesh axes as a larger flattened dimension and partition the I named axis across all the devices. The order of the multiple mesh-axis subscripts matters, as it specifies the traversal order of the partitioning across the grid.

Lastly, note that we cannot have multiple named axes sharded along the same mesh dimension. e.g. $A[I_X, J_X]$ is a nonsensical, forbidden sharding. Once a mesh dimension has been used to shard one dimension of an array, it is in a sense “spent”.
Pop Quiz: Let A be an array with shape int8[128, 2048], sharding $A[I_{XY}, J]$, and mesh Mesh({'X': 2, 'Y': 8, 'Z': 2}) (so 32 devices total). How much memory does A use per device? How much total memory does A use across all devices?
Click here for the answer.
Answer: Our array A is sharded over X and Y and replicated over Z, so per device it has shape int8[128 / (2 * 8), 2048] = int8[8, 2048], with size 8 * 2048 = 16,384 bytes. Because it’s replicated over Z, while within a Z-plane it’s fully sharded over X and Y, there are 2 complete copies of the original array (one per Z-plane). So the total size across all devices is: original array size × Z replicas = 128 * 2048 * 2 = 512 KiB total. Alternatively, we can verify this as: 32 devices × 16,384 bytes per device = 512 KiB total.
How do we describe this in code?
So far we’ve avoided talking about code, but now is a good chance for a sneak peek. JAX uses a named sharding syntax that very closely matches the abstract syntax we describe above. We’ll talk more about this in Section 10, but here’s a quick preview. You can play with this in a Google Colab here and profile the result to see how JAX handles different shardings. This snippet does 3 things:
- Creates a jax.Mesh that maps our 8 TPUs into a 4x2 grid with names ‘X’ and ‘Y’ assigned to the two axes.
- Creates matrices A and B where A is sharded along both its dimensions and B is sharded along the output dimension.
- Compiles and performs a simple matrix multiplication that returns a sharded array.
import jax
import jax.numpy as jnp
# Create our mesh! We're running on a TPU v2-8 4x2 slice with names 'X' and 'Y'.
# The Auto axis type tells JAX to let the XLA compiler infer intermediate shardings.
assert len(jax.devices()) == 8
Auto = jax.sharding.AxisType.Auto
mesh = jax.make_mesh(axis_shapes=(4, 2), axis_names=('X', 'Y'), axis_types=(Auto, Auto))
# A little utility function to help define our sharding. A PartitionSpec is our
# sharding (a mapping from axes to names).
def P(*args):
return jax.NamedSharding(mesh, jax.sharding.PartitionSpec(*args))
# We shard both A and B over the non-contracting dimension and A over the contracting dim.
A = jnp.zeros((8, 2048), dtype=jnp.bfloat16, device=P('X', 'Y'))
B = jnp.zeros((2048, 8192), dtype=jnp.bfloat16, device=P(None, 'Y'))
# We can perform a matmul on these sharded arrays! out_shardings tells us how we want
# the output to be sharded. JAX/XLA handles the rest of the sharding for us.
y = jax.jit(lambda A, B: jnp.einsum('BD,DF->BF', A, B), out_shardings=P('X', 'Y'))(A, B)
The cool thing about JAX is that these arrays behave as if they’re unsharded! B.shape will tell us the global or logical shape (2048, 8192). We have to actually look at B.addressable_shards to see how it’s locally sharded. We can perform operations on these arrays and JAX will attempt to figure out how to broadcast or reshape them to perform the operations. For instance, in the above example, the local shape of A is [2, 1024] and for B is [2048, 4096]. JAX/XLA will automatically add communication across these arrays as necessary to perform the final multiplication.
Computation With Sharded Arrays
If you have an array of data that’s distributed across many devices and wish to perform mathematical operations on it, what are the overheads associated with sharding both the data and the computation?
Obviously, this depends on the computation involved.
- For elementwise operations, there is no overhead for operating on a distributed array.
- When we wish to perform operations across elements resident on many devices, things get complicated. Thankfully, for most machine learning nearly all computation takes place in the form of matrix multiplications, and they are relatively simple to analyze.
The rest of this section will deal with how to multiply sharded matrices. To a first approximation, this involves moving chunks of a matrix around so you can fully multiply or sum each chunk. Each sharding will involve different communication. For example, $A[I_X, J] \cdot B[J, K_Y] \to C[I_X, K_Y]$ can be multiplied without any communication because the contracting dimension (J, the one we’re actually summing over) is unsharded. However, if we wanted the output unsharded (i.e. $A[I_X, J] \cdot B[J, K_Y] \to C[I, K]$), we would either need to copy $A$ and $B$ or $C$ to every device (using an AllGather). These two choices have different communication costs, so we need to calculate this cost and pick the lowest one.
You can think of this in terms of “block matrix multiplication”.
To understand this, it can be helpful to recall the concept of a “block matrix”, or a nested matrix of matrices:
\[\begin{equation} \begin{pmatrix} a_{00} & a_{01} & a_{02} & a_{03} \\ a_{10} & a_{11} & a_{12} & a_{13} \\ a_{20} & a_{21} & a_{22} & a_{23} \\ a_{30} & a_{31} & a_{32} & a_{33} \end{pmatrix} = \left( \begin{matrix} \begin{bmatrix} a_{00} & a_{01} \\ a_{10} & a_{11} \end{bmatrix} \\ \begin{bmatrix} a_{20} & a_{21} \\ a_{30} & a_{31} \end{bmatrix} \end{matrix} \begin{matrix} \begin{bmatrix} a_{02} & a_{03} \\ a_{12} & a_{13} \end{bmatrix} \\ \begin{bmatrix} a_{22} & a_{23} \\ a_{32} & a_{33} \end{bmatrix} \end{matrix} \right) = \begin{pmatrix} \mathbf{A_{00}} & \mathbf{A_{01}} \\ \mathbf{A_{10}} & \mathbf{A_{11}} \end{pmatrix} \end{equation}\]Matrix multiplication has the nice property that when the matrix multiplicands are written in terms of blocks, the product can be written in terms of block matmuls following the standard rule:
\[\begin{equation} \begin{pmatrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{pmatrix} \cdot \begin{pmatrix} B_{00} & B_{01} \\ B_{10} & B_{11} \end{pmatrix} = \begin{pmatrix} A_{00}B_{00} + A_{01}B_{10} & A_{00}B_{01} + A_{01}B_{11} \\ A_{10}B_{00} + A_{11}B_{10} & A_{10}B_{01} + A_{11}B_{11} \end{pmatrix} \end{equation}\]What this means is that implementing distributed matrix multiplications reduces down to moving these sharded blocks over the network, performing local matrix multiplications on the blocks, and summing their results. The question then is what communication to add, and how expensive it is.
Conveniently, we can boil down all possible shardings into roughly 4 cases we need to consider, each of which has a rule for what communication we need to add
- Case 1: neither input is sharded along the contracting dimension. We can multiply local shards without any communication.
- Case 2: one input has a sharded contracting dimension. We typically “AllGather” the sharded input along the contracting dimension.
- Case 3: both inputs are sharded along the contracting dimension. We can multiply the local shards, then “AllReduce” the result.
- Case 4: both inputs have a non-contracting dimension sharded along the same axis. We cannot proceed without AllGathering one of the two inputs first.
You can think of these as rules that simply need to be followed, but it’s also valuable to understand why these rules hold and how expensive they are. We’ll go through each one of these in detail now.
Case 1: neither multiplicand has a sharded contracting dimension
Lemma: when multiplying sharded matrices, the computation is valid and the output follows the sharding of the inputs unless the contracting dimension is sharded or both matrices are sharded along the same axis. For example, this works fine
\[\begin{equation*} \mathbf{A}[I_X, J] \cdot \mathbf{B}[J, K_Y] \rightarrow \mathbf{C}[I_X, K_Y] \end{equation*}\]with no communication whatsoever, and results in a tensor sharded across both the X and Y hardware dimensions. Try to think about why this is. Basically, the computation is independent of the sharding, since each batch entry has some local chunk of the axis being contracted that it can multiply and reduce. Any of these cases work fine and follow this rule:
\[\begin{align*} \mathbf{A}[I, J] \cdot \mathbf{B}[J, K] \rightarrow &\ \mathbf{C}[I, K] \\ \mathbf{A}[I_X, J] \cdot \mathbf{B}[J, K] \rightarrow &\ \mathbf{C}[I_X, K]\\ \mathbf{A}[I, J] \cdot \mathbf{B}[J, K_Y] \rightarrow &\ \mathbf{C}[I, K_Y]\\ \mathbf{A}[I_X, J] \cdot \mathbf{B}[J, K_Y] \rightarrow &\ \mathbf{C}[I_X, K_Y] \end{align*}\]Because neither A nor B has a sharded contracting dimension J, we can simply perform the local block matrix multiplies of the inputs and the results will already be sharded according to the desired output shardings. When both multiplicands have non-contracting dimensions sharded along the same axis, this is no longer true (see the invalid shardings section for details).
Case 2: one multiplicand has a sharded contracting dimension
Let’s consider what to do when one input A is sharded along the contracting J dimension and B is fully replicated:
\[\mathbf{A}[I, J_X] \cdot \mathbf{B}[J, K] \rightarrow \mathbf{C}[I, K]\]We cannot simply multiply the local chunks of A and B because we need to sum over the full contracting dimension of A, which is split across the X axis. Typically, we first “AllGather” the shards of A so every device has a full copy, and only then multiply against B:
\[\textbf{AllGather}_X[I, J_X] \rightarrow \mathbf{A}[I, J]\] \[\mathbf{A}[I, J] \cdot \mathbf{B}[J, K] \rightarrow \mathbf{C}[I, K]\]This way the actual multiplication can be done fully on each device.
Takeaway: When multiplying matrices where one of the matrices is sharded along the contracting dimension, we generally AllGather it first so the contraction is no longer sharded, then do a local matmul.
Note that when B is not also sharded along X, we could also do the local partial matmul and then sum (or AllReduce) the sharded partial sums, which lets us shard the compute but usually has a higher communication cost. This can be faster in some cases, although it’s usually true in practice that B will be sharded. Question 4 below works through when this is better.
What is an AllGather? An AllGather is the first core MPI communication primitive we will discuss. An AllGather removes the sharding along an axis and reassembles the shards spread across devices onto each device along that axis. Using the notation above, an AllGather removes a subscript from a set of axes, e.g.
\[\textbf{AllGather}_{XY}(A[I_{XY}, J]) \rightarrow A[I, J]\]We don’t have to remove all subscripts for a given dimension, e.g. \(A[I_{XY}, J] \rightarrow A[I_Y, J]\) is also an AllGather, just over only a single axis. Also note that we may also wish to use an AllGather to remove non-contracting dimension sharding, for instance in the matrix multiply:
\[A[I_X, J] \cdot B[J, K] \rightarrow C[I, K]\]We could either AllGather A initially to remove the input sharding, or we can do the sharded matmul and then AllGather the result C.
How is an AllGather actually performed? To perform a 1-dimensional AllGather around a single TPU axis (a ring), we basically have each TPU pass its shard around a ring until every device has a copy.

We can either do an AllGather in one direction or both directions (two directions are shown above). If we do one direction, each TPU sends chunks of size $\text{bytes} / N$ over $N - 1$ hops around the ring. If we do two directions, we have $\lfloor \frac{N}{2} \rfloor$ hops of size $2 \cdot \text{bytes} / N$.
How long does this take? Let’s take the bidirectional AllGather and calculate how long it takes. Let \(V\) be the number of bytes in the array, and $X$ be the number of shards on the contracting dimension. Then from the above diagram, each hop sends $V / \lvert X\rvert$ bytes in each direction, so each hop takes
\[T_{hop} = \frac{2 \cdot V}{\lvert X \rvert \cdot W_\text{ici}}\]where $W_\text{ici}$ is the bidirectional ICI bandwidth.
Note that this doesn’t depend on $X$! That’s kind of striking, because it means even though our TPUs are only locally connected, the locality of the connections doesn’t matter. We’re just bottlenecked by the speed of each link.
Takeaway: when performing an AllGather (or a ReduceScatter or AllReduce) in a throughput-bound regime, the actual communication time depends only on the size of the array and the available bandwidth, not the number of devices over which our array is sharded!
A note on ICI latency: Each hop over an ICI link has some intrinsic overhead regardless of the data volume. This is typically around 1us. This means when our array \(A\) is very small and each hop takes less than 1us, we can enter a “latency-bound” regime where the calculation does depend on $X$.
For the full details, click here.
Let \(T_\text{min}\) be the minimum time for a single hop. Then
\[T_{hop} = \max \left[ T_{min}, \frac{2 \cdot V}{X \cdot W_\text{ici}} \right]\] \[T_{total} = \max \left[ \frac{T_{min} \cdot X}{2}, \frac{V}{W_\text{ici}} \right]\]since we perform $X / 2$ hops. For large reductions or gathers, we’re solidly bandwidth bound. We’re sending so much data that the overhead of each hop is essentially negligible. But for small arrays (e.g. when sampling from a model), this isn’t negligible, and the ICI bandwidth isn’t relevant. We’re bound purely by latency. Another way to put this is that given a particular TPU, e.g. TPU v5e with 4.5e10 unidirectional ICI bandwidth, sending any buffer under 4.5e10 * 1e-6 = 45kB will be latency bound.
Here is an empirical measurement of AllGather bandwidth on a TPU v5e 8x16 slice. The array is sharded across the 16 axis so it has a full bidirectional ring.

Note that we not only achieve about 95% of the peak claimed bandwidth (4.5e10) but also that we achieve this peak at about 10MB, which when 16-way sharded gives us about 625kB per device (aside: this is much better than GPUs).
What happens when we AllGather over multiple axes? When we gather over multiple axes, we have multiple dimensions of ICI over which to perform the gather. For instance, AllGatherXY([B, DXY]) operates over two hardware mesh axes. This increases the available bandwidth by a factor of $N_\text{axes}$.
When considering latency, we end up with the general rule:
\[T_{total} = \max \left[ \frac{T_{min} \cdot \sum_{i} |X_i|}{2}, \frac{V}{W_\text{ici} \cdot N_\text{axes}} \right]\]where \(\sum_i \lvert X_i \rvert / 2\) is the length of the longest path in the TPU mesh.
Pop Quiz 2 [AllGather time]: Using the numbers from Part 2, how long does it take to perform the AllGatherY([EY, F]) → [E, F] on a TPU v5e with a 2D mesh {'X': 8, 'Y': 4}, \(E = 2048\), \(F = 8192\) in bfloat16? What about with \(E=256, F=256\)?
Click here for the answer.
Answer: Let’s start by calculating some basic quantities:
1) TPU v5e has 4.5e10 bytes/s of unidirectional ICI bandwidth for each of its 2 axes. 2) In bfloat16 for (a), we have $A[E_Y, F]$ so each device holds an array of shape bf16[512, 8192] which has 512 * 8192 * 2 = 8.4MB. The total array has size 2048 * 8192 * 2 = 34MB.
For part (1), we can use the formula above. Since we’re performing the AllGather over one axis, we have $T_{\text{comms}} = \text{34e6} / \text{9e10} = \text{377us}$. To check that we’re not latency-bound, we know over an axis of size 4, we’ll have at most 3 hops, so our latency bound is something like 3us, so we’re not close. However, TPU v5e only has a wraparound connection when one axis has size 16, so here we actually can’t do a fully bidirectional AllGather. We have to do 3 hops for data from the edges to reach the other edge, so in theory we have more like $T_{\text{comms}} = 3 * \text{8.4e6} / \text{4.5e10} = 560\mu s$. Here’s an actual profile from this Colab, which shows $680 \mu s$, which is reasonable since we’re likely not getting 100% of the theoretical bandwidth! For part (2) each shard has size 64 * 256 * 2 = 32kB. 32e3 / 4.5e10 = 0.7us, so we’re latency bound. Since we have 3 hops, this will take roughly 3 * 1us = 3us. In practice, it’s closer to 8us.
Note: when we have a 2D mesh like {'X': 16, 'Y': 4}, it is not necessary for each axis to correspond to a specific hardware axis. This means for instance the above could describe a 4x4x4 TPU v5p cube with 2 axes on the $X$ axis. This will come into play later when we describe data parallelism over multiple axes.
Case 3: both multiplicands have sharded contracting dimensions
The third fundamental case is when both multiplicands are sharded on their contracting dimensions, along the same mesh axis:
\[\textbf{A}[I, J_X] \cdot \textbf{B}[J_X, K] \rightarrow C[I, K]\]In this case the local sharded block matrix multiplies are at least possible to perform, since they will share the same sets of contracting indices. But each product will only represent a partial sum of the full desired product, and each device along the X dimension will be left with different partial sums of this final desired product. This is so common that we extend our notation to explicitly mark this condition:
\[\textbf{A}[I, J_X] \cdot_\text{LOCAL} \textbf{B}[J_X, K] \rightarrow C[I, K] \{\ U_X \}\]The notation { UX } reads “unreduced along X mesh axis” and refers to this status of the operation being “incomplete” in a sense, in that it will only be finished pending a final sum. The $\cdot_\text{LOCAL}$ syntax means we perform the local sum but leave the result unreduced.
This can be seen as the following result about matrix multiplications and outer products:
\[A \cdot B = \sum_{i=1}^{P} \underbrace{A_{:,i} \otimes B_{i,:}}_{\in \mathbb{R}^{n \times m}}\]where ⊗ is the outer product. Thus, if TPU i on axis X has the ith column of A, and the ith row of B, we can do a local matrix multiplication to obtain \(A_{:,i} \otimes B_{i,:} \in \mathbb{R}_{n\times m}\). This matrix has, in each entry, the ith term of the sum that A • B has at that entry. We still need to perform that sum over P, which we sharded over mesh axis X, to obtain the full A • B. This works the same way if we write A and B by blocks (i.e. shards), and then sum over each resulting shard of the result.
We can perform this summation using a full AllReduce across the X axis to remedy this:
\[\begin{align*} A[I, J_X] \cdot_\text{LOCAL} B[J_X, K] \rightarrow &\ C[I, K] \{ U_X \} \\ \textbf{AllReduce}_X C[I, K] \{ U_X \} \rightarrow &\ C[I, K] \end{align*}\]AllReduce removes partial sums, resulting in each device along the axis having the same fully-summed value. AllReduce is the second of several key communications we’ll discuss in this section, the first being the AllGather, and the others being ReduceScatter and AllToAll. An AllReduce takes an array with an unreduced (partially summed) axis and performs the sum by passing those shards around the unreduced axis and accumulating the result. The signature is
\[\textbf{AllReduce}_Y A[I_X, J] \{U_Y\} \rightarrow A[I_X, J]\]This means it simply removes the $\{U_Y\}$ suffix but otherwise leaves the result unchanged.
How expensive is an AllReduce? One mental model for how an AllReduce is performed is that every device sends its shard to its neighbors, and sums up all the shards that it receives. Clearly, this is more expensive than an AllGather because each “shard” has the same shape as the full array. Generally, an AllReduce is twice as expensive as an AllGather. One way to see this is to note that an AllReduce can be expressed as a composition of two other primitives: a ReduceScatter and an AllGather. Like an AllReduce, a ReduceScatter resolves partial sums on an array but results in an output ‘scattered’ or partitioned along a given dimension. AllGather collects all those pieces and ‘unpartitions/unshards/replicates’ the logical axis along that physical axis.
\[\begin{align*} \textbf{ReduceScatter}_{Y,J} : A[I_X,J] \{U_Y\} \rightarrow &\ A[I_X, J_Y] \\ \textbf{AllGather}_Y : A[I_X, J_Y] \rightarrow &\ A[I_X, J] \end{align*}\]What about a ReduceScatter? Just as the AllGather reassembles a sharded array (removing a subscript), a ReduceScatter sums an unreduced/partially summed array and then scatters (shards) a different logical axis along the same mesh axis. $X[F]\{U_Y\} \to X[F_Y]$. The animation shows how this is done: note that it’s very similar to an AllGather but instead of retaining each shard, we sum them together. Thus, its latency is roughly the same, excluding the time taken to perform the reduction.

The communication time for each hop is simply the per-shard bytes $V / Y$ divided by the bandwidth $W_\text{ici}$, as it was for an AllGather, so we have
\[T_{\text{comms per AllGather or ReduceScatter}} = \frac{V}{W_\text{ici}}\] \[T_{\text{comms per AllReduce}} = 2 \cdot \frac{V}{W_\text{ici}}\]where \(W_\text{ici}\) is the bidirectional bandwidth, so long as we have a full ring to reduce over.
Case 4: both multiplicands have a non-contracting dimension sharded along the same axis
Each mesh dimension can appear at most once when sharding a tensor. Performing the above rules can sometimes lead to a situation where this rule is violated, such as:
\[A[I_X, J] \cdot B[J, K_X] \rightarrow C[I_X, K_X]\]This is invalid because a given shard, say i, along dimension X, would have the (i, i)th shard of C, that is, a diagonal entry. There is not enough information among all shards, then, to recover anything but the diagonal entries of the result, so we cannot allow this sharding.
The way to resolve this is to AllGather some of the dimensions. Here we have two choices:
\[\begin{align*} \textbf{AllGather}_X A[I_X, J] \rightarrow &\ A[I, J] \\ A[I, J] \cdot B[J, K_X] \rightarrow &\ C[I, K_X] \end{align*}\]or
\[\begin{align*} \textbf{AllGather}_X B[J, K_X] \rightarrow &\ B[J, K] \\ A[I_X, J] \cdot B[J, K] \rightarrow &\ C[I_X, K] \end{align*}\]In either case, the result will only mention X once in its shape. Which one we pick will be based on what sharding the following operations need.
A Deeper Dive into TPU Communication Primitives
The previous 4 cases have introduced several “core communication primitives” used to perform sharded matrix multiplications:
- AllGather: removes a subscript from a sharding, gathering the shards.
- ReduceScatter: removes an “un-reduced” suffix from an array by summing shards over that axis, leaving the array sharded over a second axis.
- AllReduce: removes an “un-reduced” suffix, leaving the array unsharded along that axis.
There’s one more core communication primitive to mention that arises in the case of Mixture of Experts (MoE) models and other computations: the AllToAll.
Our final communication primitive: the AllToAll
A final fundamental collective which does not occur naturally when considering sharded matrix multiplies, but which comes up constantly in practice, is the AllToAll collective, or more precisely the special case of a sharded transposition or resharding operation. e.g.
\[\textbf{AllToAll}_{X, J} A[I_X, J] \rightarrow A[I, J_X]\]AllToAlls are typically required to rearrange sharded layouts between different regions of a sharded computation that don’t have compatible layout schemes. They arise naturally when considering sharded mixture-of-experts models. You can think of an AllToAll as moving a subscript from one axis to another. Because an all to all doesn’t need to replicate all of the data of each shard across the ring, it’s actually cheaper than an AllGather (by a factor of ¼)

If we generalize to an ND AllToAll, the overall cost for an array of $V$ total bytes (summed across all devices) on an AxBxC mesh is
\[T_\text{comms per AllToAll} = \frac{V \cdot \max(A, B, C, ...)}{4 \cdot N \cdot W_\text{ici}}\]where as usual $W_\text{ici}$ is the bidirectional ICI bandwidth and $N = A \cdot B \cdot C \cdot \ldots$ is the total number of devices. Equivalently, in terms of the per-device bytes $V / N$, the cost is $(V / N) \cdot \max(A, B, C, …) / (4 \cdot W_\text{ici})$. For a 1D mesh, this reduces to $V / (4 \cdot W_\text{ici})$, which is 1 / 4 the cost of an AllGather. In 2D, the cost actually scales down with the size of the smallest axis.
Aside: If you want a hand-wavy derivation of this fact, start with a 1D torus $\mathbb{Z} / N\mathbb{Z}$. If we pick a source and target node at random, they are on average N / 4 hops from each other, giving us a cost of $(V \cdot N) / (4 * N)$. Now if we consider an ND torus, each axis is basically independent. Each node has $1 / N$ bytes and on average has to hop its data $\max(A, B, C, …) / 4$ hops. You can also derive this from bisection bandwidth: in an AllToAll, each half of the mesh sends half its data ($V / 4$ bytes) to the other half. The narrowest bisection cuts perpendicular to the longest axis, crossing $2 \cdot N / \max(A, B, …)$ links (two cut planes, counting wraparound), for a one-directional bandwidth of $N \cdot W_\text{ici} / \max(A, B, …)$. Dividing gives the formula above.
More about the ReduceScatter
ReduceScatter is a more fundamental operation than it first appears, as it is actually the derivative of an AllGather, and vice versa. i.e. if in the forward pass we have:
\[\textbf{AllGather}_X A[I_X] \rightarrow A[I]\]Then we ReduceScatter the reverse-mode derivatives A’ (which will in general be different on each shard) to derive the sharded A’:
\[\textbf{ReduceScatter}_X A'[I] \{ U_X \} \rightarrow A'[I_X]\]Likewise, \(\text{ReduceScatter}_X(A[I] \{U_X\}) \to A[I_X]\) in the forward pass implies \(\text{AllGather}_{X}(A'[I_X]) \to A'[I]\) in the backwards pass.
For details on how AllGather and ReduceScatter are derivatives of each other, click here.
This stems from the fact that broadcasts and reductions are transposes of each other as linear operators, and AllGather and ReduceScatter are outer products (also known as Kronecker products) of broadcast and reduce, respectively. Concretely, if we have a vector $x \in \mathbb{R}^n$, any number of devices $p \in \mathbb{N}$, and we let $u = (1, \ldots, 1) \in \mathbb{R}^p$, we can define broadcast and reduce in the following way, which should match your intuitive understanding of them:
\[\begin{align*} \text{broadcast} &: \mathbb{R}^n \rightarrow \mathbb{R}^{p n} \\ \text{broadcast} &= u \otimes \mathbf{I}_n \\ \text{reduce} &: \mathbb{R}^{p n} \rightarrow \mathbb{R}^n \\ \text{reduce} &= u^T \otimes \mathbf{I}_n \end{align*}\]Let’s see how this looks in an example, where $n = 1$, $p = 2$. If $x = (7)$, we have \(\text{broadcast}(x) = \left(\begin{pmatrix} 1 \\ 1 \end{pmatrix} \otimes \begin{pmatrix} 1 \end{pmatrix}\right) x = \begin{pmatrix} 1 \\ 1 \end{pmatrix} x = \begin{pmatrix} 7\\ 7 \end{pmatrix} \in \mathbb{R}^{p n}\). This matches what we’d expect, broadcasting a vector in $\mathbb{R}^n$ to $\mathbb{R}^{pn}$. Now letting $y = (8, 9)$, we have \(\text{reduce}(y) = \left(\begin{pmatrix} 1 & 1 \end{pmatrix} \otimes \begin{pmatrix} 1\end{pmatrix}\right) y = \begin{pmatrix} 1 & 1 \end{pmatrix} \begin{pmatrix} 8 \\ 9 \end{pmatrix} = \begin{pmatrix} 17 \end{pmatrix}\). This again matches what we’d expect, reducing a vector in $\mathbb{R}^{p n}$ to a vector in $\mathbb{R}^{n}$. Since $(A \otimes B)^T = A^T \otimes B^T$ for any two matrices $A$ and $B$, we see that $\text{reduce} = \text{broadcast}^T$. We recover AllGather and ReduceScatter as the following outer products:
\[\begin{align*} \text{AllGather} &: \mathbb{R}^{p n} \rightarrow \mathbb{R}^{p^2 n} \\ \text{AllGather} &= \text{broadcast} \otimes \mathbf{I}_p \\ \text{ReduceScatter} &= \mathbb{R}^{p^2 n} \rightarrow \mathbb{R}^{p n} \\ \text{ReduceScatter} &= \text{reduce} \otimes \mathbf{I}_p \end{align*}\]Here we think of $\mathbb{R}^{p^2 n}$ as $\mathbb{R}^{p \times p n}$, so one $\mathbb{R}^{p n}$ vector for each of our $p$ devices. We suggest playing around with small examples, say $n = 2$, $p = 3$, to see what these operators look like as matrices. Using the same transposition property, we once more obtain $\text{AllGather}^T = \text{ReduceScatter}$, and of course $\text{ReduceScatter}^T = \text{AllGather}$. This transposition will arise during backpropagation, since if we have $y = Ax$ for some linear operator $A$, such as AllGather or ReduceScatter, then during backpropagation we will have the derivative of the loss with respect to $y$, $\frac{\partial L}{\partial y}$, and we obtain $\frac{\partial L}{\partial x}$ as $\frac{\partial L}{\partial x} = A^T \frac{\partial L}{\partial y}$. This shows how the derivative of AllGather will be ReduceScatter, and vice versa.
Turning an AllReduce into an AllGather and ReduceScatter also has the convenient property that we can defer the final AllGather until some later moment. Very commonly we’d rather not pay the cost of reassembling the full matrix product replicated across the devices. Rather we’d like to preserve a sharded state even in this case of combining two multiplicands with sharded contracting dimensions:
\[A[I, J_X] \cdot B[J_X, K] \rightarrow C[I, K_X]\]In this case, we can also perform a ReduceScatter instead of an AllReduce, and then optionally perform the AllGather at some later time, i.e.
\[\begin{align*} A[I, J_X] \cdot_{LOCAL} B[J_X, K] \rightarrow &\ C[I, K] \{ U_X \} \\ \textbf{ReduceScatter}_{X,K} C[I, K] \{ U_X \} \rightarrow &\ C[I, K_X] \end{align*}\]Note that ReduceScatter introduces a sharded dimension, and so has a natural freedom to shard along either the I or K named dimensions in this case. We generally need to choose which named dimension to introduce a new sharding to when using a ReduceScatter (though the choice is usually forced by the larger modeling context). This is why we use the syntax ReduceScatterX,K to specify the axis to shard.
How to overlap matmul communication with compute
As we discussed in Part 1, we generally assume we can always overlap communication with some useful computation if the comms are fast enough. The collectives in this section generally can be overlapped with the matrix multiplication compute itself, but doing so is non-trivial. The algorithm we use is something called a collective matmul, first described in Wang et al.. Here is a simplified animation of how this overlap can be implemented:

To put it simply, we can do the matmul for one chunk of the matrix while starting the ring reduction for previous chunks. In some cases we can also tile over the batch dimension or matrix input dimension. We work through a simple JAX implementation in Part 10 and the Mosaic docs also give a good example on GPU. We encourage you to implement a version of this at some point.
What Have We Learned?
- The sharding of an array is specified by a Mesh that names the physical, hardware axes of our TPU mesh and a Sharding that assigns mesh axis names to the logical axes of the array.
- For example, A[IXY, J] describes an abstract array A with its first dimension sharded along two mesh axes X and Y. Combined with Mesh(mesh_shape=(4, 8), axis_names=(‘X’, ‘Y’)) or the abbreviated Mesh({‘X’: 4, ‘Y’: 8}), this tells us our array is sharded 32 ways along the first dimension.
-
Arithmetic with sharded arrays works exactly like with unsharded arrays unless you perform a contraction along a sharded axis. In that case, we have to introduce some communication. We consider four cases:
- Neither array is sharded along the contracting dimension: no communication is needed.
- One array is sharded along the contracting dimension (or the contracting dimensions are sharded along different axes): we AllGather one of the inputs before performing the operation.
- Both arrays are identically sharded along the contracting dimension: we multiply the shards locally then perform an AllReduce or ReduceScatter.
- Both arrays are sharded along the same mesh axis along a non-contracting dimension: we AllGather one of the inputs first.
- TPUs use roughly 4 core communication primitives:
- AllGather: $[A_X, B] \to [A, B]$
- ReduceScatter: $[A, B] \{U_X\} \to [A_X, B]$
- AllToAll: $[A, B_X] \to [A_X, B]$
- AllReduce: $[A_X, B]\{U_Y\} \to [A_X, B]$ (technically not a primitive since it combines a ReduceScatter + AllGather)

- The cost and latency of each of these operations doesn’t depend on the size of the axis (as long as they’re bandwidth bound), but only on the size of the input arrays and the bandwidth of the link. For a unidirectional AllGather/ReduceScatter:
- An AllReduce is composed of a ReduceScatter followed by an AllGather, and thus has 2x the above cost. An AllToAll only has to pass shards part-way around the ring and is thus ¼ the cost of an AllGather. Here’s a summary:
| Operation | Description | Syntax | Runtime |
|---|---|---|---|
| AllGather | Gathers all the shards of a sharded array along an axis, removing a subscript. | $[A_X, B] \to [A, B]$ | bytes / (bidirectional ICI bandwidth * num_axes) |
| ReduceScatter | Sums a partially summed array along an axis and shards it along another axis (adding a subscript). | $[A, B] \{U_X\} \to [A_X, B]$ | Same as AllGather |
| AllReduce | Sums a partially summed array along an axis. Removes a { Ux }. Combines an AllGather and ReduceScatter. | $[A_X, B]\{U_Y\} \to [A_X, B]$ | 2 * AllGather |
| AllToAll | Gathers (replicates) an axis and shards a different dimension along the same axis. | $[A, B_X] \to [A_X, B]$ | AllGather / 4 for a bidirectional ring |
Some Problems to Work
Here are some instructive problems based on content in this section. We won’t include all answers at the moment but we’ll write up more answers as we can.
Question 1 [replicated sharding]: An array is sharded $A[I_X, J, K, \ldots]$ (i.e., only sharded across $X$), with a mesh Mesh({'X': 4, 'Y': 8, 'Z': 2}). What is the ratio of the total number of bytes taken up by $A$ across all chips to the size of one copy of the array?
Click here for the answer.
Our array is only sharded along X, which has size 4, so effectively each shard has size $[I / 4, J, K, \ldots] = \text{sizeof}(A) / 4$. Since our array is replicated across Y and Z, the total size is $Y \cdot Z \cdot \text{sizeof}(A)$, so the ratio of total size to single chip size is $Y \cdot Z \cdot \text{sizeof}(A) / \text{sizeof}(A) = 16$.
Question 2 [AllGather latency]: How long should $\text{AllGather}_X([B_X, D_Y])$ take on a TPU v4p 4x4x4 slice with mesh Mesh({'X': 4, 'Y': 4, 'Z': 4}) if $B=1024$ and $D=4096$ in bfloat16? How about \(\text{AllGather}_{XY}([B_X, D_Y])\)? How about \(\text{AllReduce}_Z([B_X, D_Y] \{U_Z \})\)?
Click here for the answer.
We have a wraparound link on all axes because we have a full 4x4x4 cube, so we have 9e10 bidirectional bandwidth to work with.
-
Because we’re just gathering over one axis and the other is sharded, we’re effectively gathering $2BD / Y$ bytes over 1 axis. If you think about just a single shard along the Y-axis, the AllGather along X looks like an unsharded AllGather with 1 / Y of the bytes. Since our ICI bandwidth for TPU v4p is 9e10 bytes/second bidirectional, this will take $2BD / (\text{9e10} \cdot Y) = 2 \cdot 1024 \cdot 4096 / (\text{9e10} \cdot 4) = 23 \mu s$.
-
We have twice the bandwidth as before but we’re AllGathering the full array, so
T = 2BD / (2 * W) = 2*1024*4096 / (2 * 9e10) = 46us. This is far from the latency bound of 4us (1us per hop), so we’re fine. -
The cost of an AllReduce is twice that of an AllGather. Each shard has size $2BD / (X * Y)$, so the cost is about $4BD / (X * Y * W)$, or roughly
4 * 1024 * 4096 / (16 * 9e10) = 11.6us.
Fun fact: parts (1) and (2) aren’t actually optimal, because the array is also replicated along the unused Z axis, and we can exploit those idle links: we can first re-shard $[B_X, D_Y] \to [B_{XZ}, D_Y]$ for free (each device just drops part of its shard) and then perform \(\text{AllGather}_{XZ}\) (or \(\text{AllGather}_{XYZ}\)), reaching the same final state while gathering over more axes. This cuts part (1) to 11.5us and part (2) to 31us — in practice you’d get this by just sharding over more axes up front, which is one reason to shard arrays as finely as possible.
Question 3 [latency-bound AllGather]: Let’s say we’re performing an $\text{AllGather}_X([B_X])$ but $B$ is very small (say 128). How long should this take on a TPU v4p 4x4x4 slice with mesh Mesh({'X': 4, 'Y': 4, 'Z': 4}) in bfloat16? Hint: you’re probably latency bound.
Click here for the answer.
Our array in bfloat16 uses only 256 bytes total, and only 64 per device. Since we have an axis of size 4 on a TPU v4p, we have a wraparound link, so we can send the array in both directions. With 4.5e10 of unidirectional bandwidth, each hop would take roughly 64 / 4.5e10 ~ 0, so we’re definitely latency bound. Counting the number of hops, we can do the full gather in only 2 hops, so roughly 2us a good estimate.
Question 4 [matmul strategies]: To perform $X[B, D] \cdot_D Y[D_X, F] \to Z[B, F]$, in this section we tell you to perform $\text{AllGather}_X(Y[D_X, F])$ and multiply the fully replicated matrices (Case 2, Strategy 1). Instead, you could multiply the local shards like $X[B, D_X] \cdot_D Y[D_X, F] \to Z[B, F] \{U_X\}$ (Case 3, Strategy 2), and then $\text{AllReduce}_X(Z[B, F] \{ U_X\})$. How many FLOPs and comms does each of these perform? Which is better and why?
Click here for the answer.
Let’s start with our baseline (Strategy 1). As we’ve shown, the cost of the AllGather is $2DF / W_\text{ici}$. Once we have the fully replicated arrays, the total compute time is $2BDF / C$ (where $C$ is our accelerator FLOPs/s, since each TPU does the same FLOPs). So we have
\[T_\text{total (Strategy 1)} = \max\left(\frac{2BDF}{C}, \frac{2DF}{W_\text{ici}}\right)\]By comparison, the new strategy (Strategy 2) does an AllReduce over $2BF$ bytes, which has cost $4BF / W_\text{ici}$ but does $1 / X$ fewer FLOPs (since the computation is sharded). This means we do $2\cdot B\cdot D\cdot F / X$ FLOPs and the resulting AllReduce communicates \(2 \cdot 2 \cdot B \cdot F\) bytes in bfloat16. Thus, our total time for Strategy 2 (no AllGather, just an AllReduce later on) is roughly
\[T_\text{total} = \max\left(\frac{2BDF}{X \cdot C}, \frac{4BF}{W_\text{ici}}\right)\]The question is: which of these is bigger? Strategy (2) is compute bound when $D / (X \cdot C) > 2 / W_\text{ici}$, or when $D / 2X > C / W_\text{ici} \approx 2550 \rightarrow X < D / (2 * 2550)$. We might reasonably expect $D \approx 8k$, so this would mean roughly $X < 2$ which is unlikely – hence we’re basically always comms bound with Strategy 2. With the baseline (Strategy 1), we’re comms bound when \(B < C / W_\text{ici} = 2550\) which is often but not always true.
So if $B < 2550$, we’re comms-bound in both cases and we have
\[T_\text{comms for Strategy 2} < T_\text{comms for Strategy 1} \Leftrightarrow \frac{4BF}{W_\text{ici}} < \frac{2DF}{W_\text{ici}}\]which is true when $D > 2B$ where $2B < 5100$. This is often true, so Strategy 2 can sometimes be better if our batch is small. When our batch is large ($B > 2550$), we have
\[T_\text{comms for Strategy 2} < T_\text{math for Strategy 1} \Leftrightarrow \frac{4BF}{W_\text{ici}} < \frac{2BDF}{C}\]This is true when $2 / W_\text{ici} < D / C$, or when $D > 2 * 2550 = 5100$, which is usually true for large models. So this alternative strategy is typically better for large models, unless $D$ is small.
Why don’t we always do this? Well, in practice we may do this sometimes, but it’s typically rare to have the contracting dimension of one of the inputs to a matmul sharded along an axis that the other input isn’t sharded over. For instance, if we’re doing FSDP (explained in Section 5), we’ll shard our parameters over the data dimension but our activations will also be sharded along data. So in this sense this doesn’t show up much.
Question 5 [minimum latency]: Let’s say I want to do a matmul $A[I, J] \cdot_J B[J, K] \to C[I, K]$ on a TPU v4p 4x4x4 with the lowest possible latency. Assume the inputs can be sharded arbitrarily but the result should be fully replicated. How should my inputs be sharded? What is the total FLOPs and comms time?
Click here for the (partial) answer.
We won’t provide a full answer here, but we’ll start by describing the four most likely options:
- $A[I_{XYZ}, J] \cdot B[J, K]$ + AG at the end
- $A[I, J] \cdot B[J, K_{XYZ}]$ + AG at the end
- $A[I, J_{XYZ}] \cdot B[J_{XYZ}, K]$ + AR at the end
- $A[I, J] \cdot B[J, K]$ (fully replicated)
We could also consider sharding different axes along different mesh axes, but that isn’t likely to change the final cost. For all but (4), the total FLOPs per TPU is the same, but comms are different for each. We then simply need to calculate the comms cost for each and see which is lowest. The TLDR is that (1) and (2) are equally good.
Question 6: Let’s say we want to perform $A[I_X, J_Y] \cdot_J B[J_Y, K] \to C[I_X, K]$ on TPU v5e 4x4. What communication do we perform? How much time is spent on communication vs. computation?
- What about $A[I_X, J] \cdot_J B[J_X, K_Y] \to C[I_X, K_Y]$? This is the most standard setting for training where we combine data, tensor, and ZeRO sharding.
- What about $A[I_X, J] \cdot_J B[J, K_Y] \to C[I_X, K_Y]$? This is standard for inference, where we do pure tensor parallelism (+data).
Question 7: A typical Transformer block has two matrices $W_\text{in}[D, F]$ and $W_\text{out}[F, D]$ where $F \gg D$. Say we have a batch size B. Then the full block is $In[B, D] \cdot W_\text{in}[D, F] \cdot W_\text{out}[F, D]$. Let’s pick $D=8192$, $F=32768$, and $B=128$ and assume everything is in bfloat16. Assume we’re running on a TPU v5e 2x2 slice but let’s pretend each TPU only has 300MB of free memory. How should In, $W_\text{in}$, $W_\text{out}$, and Out be sharded to stay below the memory limit while minimizing overall time? How much time is spent on comms and FLOPs? Hint: the final output doesn’t need to be fully replicated, but it should be sharded the same as the input so the “layer” can be repeated.
Click here for the (partial) answer.
First let’s think about memory. Each of our two big matrices uses 2 * 8192 * 32768 = 536MB. Our activations In have size 2 * 128 * 8192 = 2MB (small enough not to worry about). Since we only have 300MB of spare memory in each device, we clearly need to shard our matmuls.
- $In[B_X, D] * W_\text{in}[D_{XY}, F] * W_\text{out}[F, D_{XY}] \rightarrow Out[B_X, D]$ (this is often called FSDP)
- $In[B, D_{XY}] * W_\text{in}[D, F_{XY}] * W_\text{out}[F_{XY}, D] \rightarrow Out[B, D_{XY}]$ (this is called tensor parallelism)
The first is pretty bad because we need to AllGather our big weights or our activations first. The second requires an AllGather at the beginning and a ReduceScatter at the end (which is cheaper than an AllReduce). I’ll leave it as an exercise to do the rest of the math.
Question 8 [challenge]: Using the short code snippet above as a template, allocate a sharded array and benchmark each of the 4 main communication primitives (AllGather, AllReduce, ReduceScatter, and AllToAll) using pmap or shard_map. You will want to use jax.lax.all_gather, jax.lax.psum, jax.lax.psum_scatter, and jax.lax.all_to_all. Do you understand the semantics of these functions? How long do they take?
Question 9 [another strategy for sharded matmuls?]: Above we claimed that when only one input to a matmul is sharded along its contracting dimension, we should AllGather the sharded matrix and perform the resulting contraction locally. Another strategy you might think of is to perform the sharded matmul and then AllReduce the result (as if both inputs were sharded along the contracting dimension), i.e. $A[I, J_X] *_J B[J, K] \to C[I, K]$ by way of
- $C[I, K] \{ U_X \} = A[I, J_X] \cdot B[J_X, K]$
- $C[I, K] = \text{AllReduce}(C[I, K] \{ U_X\})$
Answer the following:
- Explicitly write out this algorithm for matrices $A[N, M]$ and $B[M, K]$, using indices to show exactly what computation is done on what device. Assume $A$ is sharded as $A[I, J_X]$ across ND devices, and you want your output to be replicated across all devices.
- Now suppose you are ok with the final result not being replicated on each device, but instead sharded (across either the N or K dimension). How would the algorithm above change?
- Looking purely at the communication cost of the strategy above (in part 2, not 1), how does this communication cost compare to the communication cost of the algorithm in which we first AllGather A and then do the matmul?
Click here for the answer.
- First compute the outer products, storing the result in \(O[N, K]: o_{kj} = \sum_i a_{ki} b_{ij}\). Note that the repeated index is not the one being contracted, as we are doing an outer product. Here the sum ranges across the set of i values stored on the particular device we are using. So, for example, if we have a contracting axis of size 16, and 4 devices, then on device 0, i would range from {0, 1, 2, 3}; on device 1, i would range from {4, 5, 6, 7}; on device 2, i would range from {8, 9, 10, 11}; and on device 3, i would range from {12, 13, 14, 15}. Then AllReduce the partial-sums of $O[N, K]$ which live on each device, to form the full $O[N, K]$.
- Instead of doing an AllReduce in step 2, we could get away with a cheaper ReduceScatter, along either axis: $[N, K] \{ U_X \} \to [N_X, K]$ or $[N, K] \{ U_X \} \to [N, K_X]$.
- As described in the main text above, the cost of doing an AllGather (when we are throughput-bound) is the same as that of a ReduceScatter; it is simply given by the size of the full matrix we are processing. So in the gather-then-matmul algorithm, this scales as $NM$ (since we are $\text{AllGather}$-ing $A$); in the matmul-then-reduce-scatter algorithm, this scales as NK (since we are reduce-scattering $O$). So the communication cost ratio of the two algorithms is
M/K.
Question 10: Fun with AllToAll: In the table above, it was noted that the time to perform an AllToAll is a factor of 4 lower than the time to perform an AllGather or ReduceScatter (in the regime where we are throughput-bound). In this problem we will see where that factor of 4 comes from, and also see how this factor would change if we only had single-direction ICI links, rather than bidirectional ICI links.
- Let’s start with the single-direction case first. Imagine we have D devices in a ring topology and want to do either an AllGather or a ReduceScatter on an N x N matrix $A[I_X, J]$ (say $D$ divides $N$ for simplicity). Describe the comms involved in these two collectives, and calculate the total number of scalars (floats or ints) which are transferred across a single ICI link during the entirety of this algorithm.
- Now let’s think about an AllToAll, still in the single-directional ICI case. How is the algorithm different in this case than the all-gather case? Calculate the number of scalars that are transferred across a single ICI link in this algorithm.
- You should have found that the ratio between your answers to part (a) and part (b) is a nice number. Explain where this factor comes from in simple terms.
- Now let’s add bidirectional communication. How does this affect the total time needed in the all-gather case?
- How does adding bidirectional communication affect the total time needed in the AllToAll case?
- Now simply explain the ratio between AllGather time and AllToAll time in a bidirectional ring.
Click here for the answer.
(1) Solution: The process is simple: in each step of the algorithm, each device will send a single-shard “strip” of the matrix (totalling \(\frac{N}{D} \times N\) elements in size) to its nearest neighbor. This occurs \(D-1\) times, since each shard needs to be communicated to all of the devices except the one it starts out on. So in total, \(\frac{N^2(D-1)}{D}\) scalars are transferred by each device, i.e. flow across a single ICI link.
Answer: \(N^2 (1-\frac{1}{D})\), or simply \(N^2\) when \(D >> 1\).
(2) Solution: The key difference between an AllToAll and an AllGather, from the perspective of communications, is that in an AllToAll, the entirety of the shard that lives on a particular device does not need to be communicated to every other device. Imagine the shard stored on a particular device (call it device 0) is \([A, B, C, D]\) (here A,B,C,D are matrices and we are imagining a ring with 4 devices for illustration). Now the matrix \(A\) does not need to be communicated anywhere, the matrix \(B\) needs to end up on device 1; matrix \(C\) ends up on device 2; and matrix \(D\) ends up on device 3. So in the first step of the algorithm, we send \(B\), \(C\), and \(D\) to device 1; in the next step, device 1 sends \(C\) and \(D\) onwards to device 2; in the final step, device 2 sends just \(D\) on to device 3. The total number of parameters transferred in this case is \((\text{size of A/B/C/D}) * (3 + 2 + 1)\). The size of A/B/C/D is (in the general case now) \(\frac{N^2}{D^2}\), and again in the general case the \((3 + 2 + 1)\) term becomes \(((D-1) + (D-2) + … + 1)\), or \(\frac{(D)(D-1)}{2}\). So the total number of bytes transferred across a single ICI link is \(\frac{N^2(D-1)}{D \times 2}\).
Answer: \(\frac{N^2}{2}(1-\frac{1}{D})\), or simply \(\frac{N^2}{2}\) when \(D >> 1\).
(3) Solution: The factor is simply \(\frac{1}{2}\), i.e. an AllToAll is half as costly as an all-gather/ReduceScatter on a unidirectional ring topology. Looking over the derivations above, this ultimately came from the fact that in the all-gather case, we are transferring the same sized block each of \((D-1)\) times, i.e. we’re doing the sum \(\text{tiny block size} * (D + D + D + … + D)\), whereas in the AllToAll case, we’re doing the sum \(\text{tiny block size} * (D + D-1 + D-2 + … + 1)\). The factor of two thus essentially comes from the fact that \(1 + 2 + \ldots + n = n(n+1)/2\).
(4) Solution: The total number of scalars that any one link has to carry now reduces by a factor of 2, since in a bidirectional ring, each “sharded strip” can be sent two ways simultaneously.
(5) Solution: In this case, we win a factor of 4 compared to the unidirectional case. This is easiest to see by considering the fate of each of the size-(N2/D2) blocks in a single sharded strip, say the one which originates on device 0. Instead of (as in the unidirectional case) sending one of these blocks a distance of D-1, another block a distance D - 2, etc. all the way to 1, we now divide the strip into blocks which move right or left, moving a maximum distance of floor(D/2). So the corresponding sum now becomes \(D/2 + D/2 - 1 + D/2 - 2 + … = D/2 \cdot (D/2+1)/2\), or \(D^2/8\) in the limit of large \(D\). Compare this to \(D^2/2\) in the unidirectional case, and we see that we’ve won a factor of 4.
(6) Solution: In a unidirectional ring, we saw that the AllToAll time was already twice as fast as the all-gather time; this comes from the fact that we don’t need to send our full strip to every single device. Then, when we added bidirectionality, we saw that it was a 4x win for AllToAll, and only a 2x win for all-gathers. Putting these ratios together, we get our sought after factor of 4.